Worked Example for New Object orientated syntax for Ruffus in Version 2.6¶
Ruffus Pipelines can now be created and manipulated directly using Pipeline and Task objects instead of via decorators.
For clarity, we use named parameters in this example. You can just as easily pass all parameters by position.
Worked example¶
Note
Remember to look at the example code:
This example pipeline is a composite of three separately subpipelines each created by a python function make_pipeline1() which is joined to another subpipeline created by make_pipeline2()
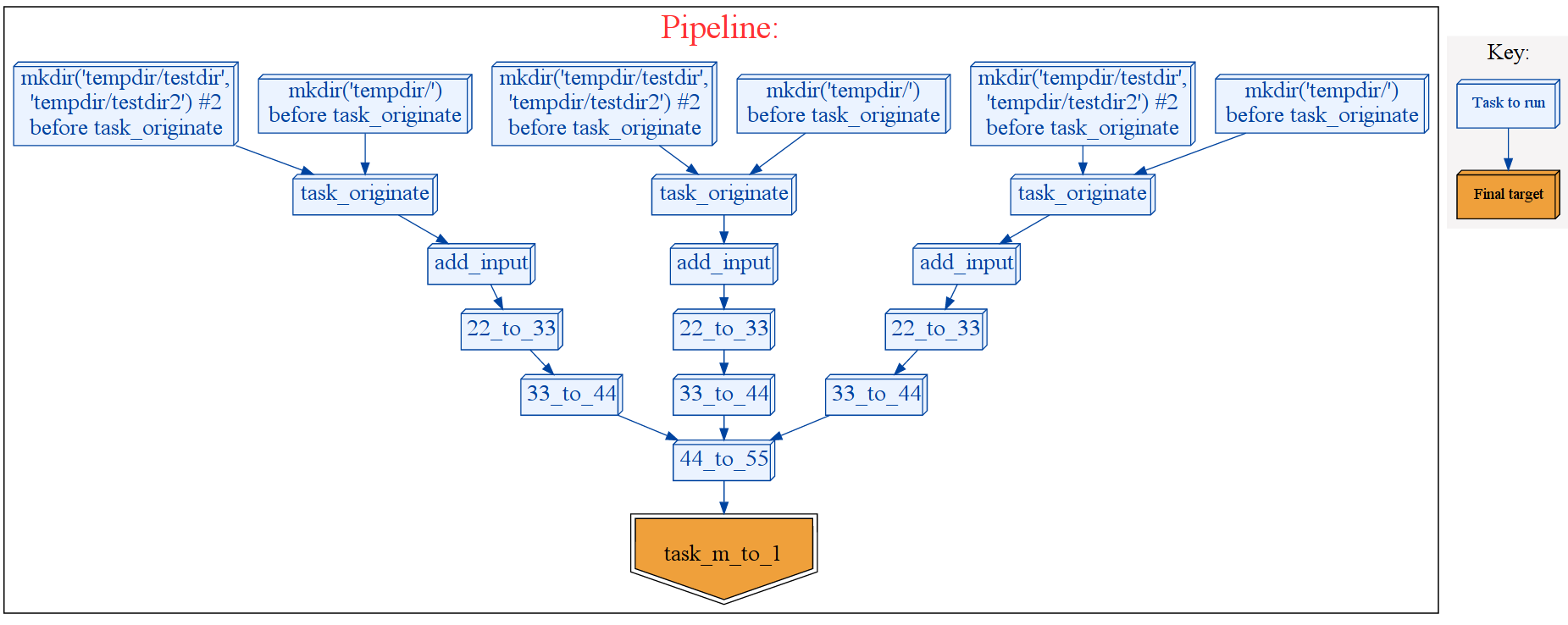
Although there are 13 different stages to this pipeline, we are using the same three python functions (but supplying them with different data).
def task_originate(o): # Makes new files ... def task_m_to_1(i, o): # Merges files together ... def task_1_to_1(i, o): # One input per output ...
Pipeline factory¶
Let us start with a python function which makes a full formed sub pipeline useable as a modular building block
# Pipelines need to have a unique name def make_pipeline1(pipeline_name, starting_file_names): passNote that we are passing the pipeline name as the first parameter.
All pipelines must have unique names
test_pipeline = Pipeline(pipeline_name) new_task = test_pipeline.originate(task_func = task_originate, output = starting_file_names)\ .follows(mkdir(tempdir), mkdir(tempdir + "testdir", tempdir + "testdir2"))\ .posttask(touch_file(tempdir + "testdir/whatever.txt"))A new task is returned from test_pipeline.originate(...) which is then modified via .follows(...) and .posttask(...). This is familiar Ruffus syntax only slightly rearranged.
We can change the output=starting_file_names later using set_output() but sometimes it is just more convenient to pass this as a parameter to the pipeline factory function.
Note
The first, mandatory parameter is task_func = task_originate which is the python function for this task
Three different ways of referring to input Tasks¶
Just as in traditional Ruffus, Pipelines are created by setting the input of one task to (the output of) its predecessor.
test_pipeline.transform(task_func = task_m_to_1, name = "add_input", # Lookup Task from function task_originate() # Needs to be unique in the pipeline input = task_originate, filter = regex(r"(.*)"), add_inputs = add_inputs(tempdir + "testdir/whatever.txt"), output = r"\1.22") test_pipeline.transform(task_func = task_1_to_1, name = "22_to_33", # Lookup Task from unique Task name = "add_input" # Function name is not unique in the pipeline input = output_from("add_input"), filter = suffix(".22"), output = ".33") tail_task = test_pipeline.transform(task_func = task_1_to_1, name = "33_to_44", # Ask test_pipeline to lookup Task name = "22_to_33" input = test_pipeline["22_to_33"], filter = suffix(".33"), output = ".44")
Head and Tail Tasks¶
# Set the tail task: test_pipeline can be used as an input # without knowing the details of task names # # Use Task object=tail_task directly test_pipeline.set_tail_tasks([tail_task]) # Set the head task: we can feed input into test_pipeline # without knowing the details of task names test_pipeline.set_head_tasks([test_pipeline[task_originate]]) return test_pipelineBy calling set_tail_tasks and set_head_tasks to assign the first and last stages of test_pipeline, we can later use test_pipeline without knowing its component Tasks.
The last step is to return the fully formed pipeline instance
Another Pipeline factory¶
# # Returns a fully formed sub pipeline useable as a building block # def make_pipeline2( pipeline_name = "pipeline2", do_not_define_head_task = False): test_pipeline2 = Pipeline(pipeline_name) test_pipeline2.transform(task_func = task_1_to_1, # task name name = "44_to_55", # placeholder: will be replaced later with set_input() input = None, filter = suffix(".44"), output = ".55") test_pipeline2.merge( task_func = task_m_to_1, input = test_pipeline2["44_to_55"], output = tempdir + "final.output",) # Lookup task using function name # This is unique within pipeline2 test_pipeline2.set_tail_tasks([test_pipeline2[task_m_to_1]]) # Lookup task using task name test_pipeline2.set_head_tasks([test_pipeline2["44_to_55"]]) return test_pipeline2make_pipeline2() looks very similar to make_pipeline1 except that the input for the head task is left blank for assigning later
Note that we can use task_m_to_1 to look up a Task (test_pipeline2[task_m_to_1]) even though this function is also used by test_pipeline. There is no ambiguity so long as only one task in test_pipeline2 uses this python function.
Creating multiple copies of a pipeline¶
Let us call make_pipeline1() to make two completely independent pipelines ("pipeline1a" and "pipeline1b")
# First two pipelines are created as separate instances by make_pipeline1() pipeline1a = make_pipeline1(pipeline_name = "pipeline1a", starting_file_names = [tempdir + ss for ss in ("a.1", "b.1")]) pipeline1b = make_pipeline1(pipeline_name = "pipeline1b", starting_file_names = [tempdir + ss for ss in ("c.1", "d.1")])We can also create a new instance of a pipeline by “cloning” an existing pipeline
# pipeline1c is a clone of pipeline1b pipeline1c = pipeline1b.clone(new_name = "pipeline1c")Because "pipeline1c" is a clone of "pipeline1b", it shares exactly the same parameters. Let us change this by giving "pipeline1c" its own starting files.
We can do this for normal (e.g. transform, split, merge etc) tasks by calling
transform_task.set_input(input = xxx)@originate doesn’t take input but creates results specified in the output parameter. To finish setting up pipeline1c:
# Set the "originate" files for pipeline1c to ("e.1" and "f.1") # Otherwise they would use the original ("c.1", "d.1") pipeline1c.set_output(output = [tempdir + ss for ss in ("e.1", "f.1")])We only create one copy of pipeline2
pipeline2 = make_pipeline2()
Connecting pipelines together¶
Because we have previously assigned head and tail tasks, we can easily join the pipelines together:
# Join all pipeline1a-c to pipeline2 pipeline2.set_input(input = [pipeline1a, pipeline1b, pipeline1c])
Running a composite pipeline¶
Ruffus automatically follows the antecedent dependencies of each task even if they are from another pipeline.
This means that you can run composite pipelines seamlessly, without any effort:
# Only runs pipeline1a pipeline1a.run() # Runs pipeline1a,b,c -> pipeline2 pipeline2.run(multiprocess = 10, verbose = 0)Note
Remember to look at the example code: